File 文件系统
文件操作是开发过程中并不可少的一部分。
- Node.js 中
fs模块是文件操作的封装,它提供了文件读取、写入、更名、删除、遍历目录、链接等 POSIX 文件系统操作。 - 与其它模块不同的是,
fs模块中所有的操作都提供了异步和同步的两个版本,具有sync后缀的方法为同步方法,不具有sync后缀的方法为异步方法。
文件常识
计算机中关于系统和文件的一些常识
- 权限位 mode
- 标识位 flag
- 文件描述符 fs
权限位 mode
因为 fs 模块需要对文件进行操作,会涉及到操作权限的问题,所以需要先清楚文件权限是什么,都有哪些权限。
文件权限表:
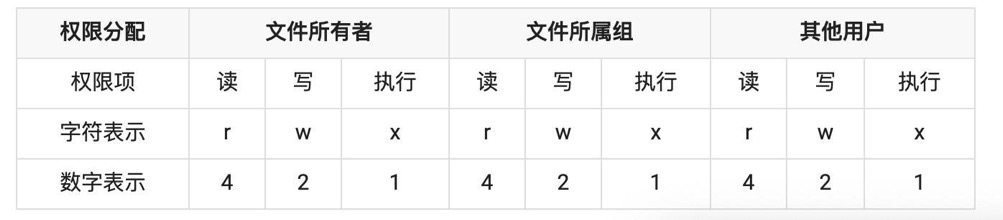
从上表中,可以得知系统针对三种类型进行权限分配,即文件所有者(自己)、文件所属组(家人)和其它用户(陌生人),文件操作权限又分为三种,读、写和执行,数字表示为八进制数,具备权限的八进制数分别为 4、2 和 1,不具备权限为 0。
为了方便理解,我们可以随便在一个目录中打开 Git,使用 Linux 命令 ls -al 来查看目录中文件和文件夹的权限位。
-rw-r--r-- 1 mrsingsing staff 1072 May 7 09:53 LICENSE-rw-r--r--@ 1 mrsingsing staff 2476 Sep 5 23:40 README.md
从上面的目录信息中,很容易看出用户名、创建时间和文件名等信息,但最重要的是开头第一项(十位的字符)。
第一位代表是文件还是文件夹,d 开头代表文件夹,- 开头的代表文件,而后面九位就代表当前用户、用户所属组和其它用户的权限位,按每三位划分,分别代表:读(r)、写(w)和执行(x),- 代表没有当前位对应的权限。
权限参数 mode 主要针对 Linux 和 Unix 操作系统,Window 的权限默认是可读、可写、不可执行,所以权限位数字表示为 0o666,转换十进制表示为 438。
标识位 flag
Node.js 中,标识位代表着对文件的操作方式,如可读、可写、既可读又可写等等。
| 符号 | 含义 |
|---|---|
| r | 读取文件,如果文件不存在则抛出异常。 |
| r+ | 读取并写入文件,如果文件不存在则抛出异常。 |
| rs | 读取并写入文件,指示操作系统绕开本地文件系统缓存。 |
| w | 写入文件,文件不存在会被创建,存在则清空后写入。 |
| wx | 写入文件,排它方式打开。 |
| w+ | 读取并写入文件,文件不存在则创建文件,存在则清空后写入。 |
| wz+ | 和 w+ 类似,排他方式打开。 |
| a | 追加写入,文件不存在则创建文件。 |
| ax | 与 a 类似,排他方式打开。 |
| a+ | 读取并追加写入,不存在则创建。 |
| ax+ | 与 a+ 类似,排他方式打开。 |
上面表格就是这些标识位的具体字符和含义,但是 flag 是不经常使用的,不容易被记住,所以在下面总结了一个加速记忆的方法。
r:读取w:写入s:同步+:增加相反操作x:排他方式
r+ 和 w+ 的区别,当文件不存在时,r+ 不会创建文件,而会抛出异常,但 w+ 会创建文件;如果文件存在,r+ 不会自动清空文件,但 w+ 会自动把已有文件的内容清空。
文件描述符 fs
操作系统会为每个打开的文件分配一个名为文件描述符的数值标识,文件操作使用这些文件描述符来识别与追踪每个特定的文件,Window 系统使用了一个不同但概念类似的机制来追踪资源,为方便用户,NodeJS 抽象了不同操作系统间的差异,为所有打开的文件分配了数值的文件描述符。
在 Node.js 中,每操作一个文件,文件描述符是递增的,文件描述符一般从 3 开始,因为前面有 0、1、2 三个比较特殊的描述符,分别代表 process.stdin(标准输入)、process.stdout(标准输出)和 process.stderr(错误输出)。
文件流
若要处理数据,流(Stream)在 Node.js 中是最好的。
- source:数据来源对象
- pipeline:数据流向的过程
- sink:数据最后存放的地方
Know more Stream Handbook
文件权限
使用 fs.access 的目的是为了检查指定文件或者目录的用户权限。
可供权限检查的常量:
fs.constants.F_OK:检查该文件在进程中是否可见fs.constants.R_OK:检查该文件在进程中是否可读fs.constants.W_OK:检查该文件在进程中是否可写fs.constants.X_OK:检查该文件在进程中是否可执行
在使用 fs.open 执勤啊,可食用 fs.access 去检查文件的可访问性,但 fs.readFile 和 fs.writeFile 不推荐(使用 fs.access 去检查)。
理由很简单,如果你这么做,就会引入了一个竞态条件。在查询权限和操作文件中相互竞争,另外的进程可能已经修改了那个文件。
相反,你应该直接打开这文件并在这处理可能出现的错误。
监听文件
使用 fs.watch,当(被监听的)文件或者目录有变化时,你会收到通知。
然而,fs.watch 这个 API 无法跨平台百分百一致,在某些系统中根本就不可用。
回调函数中的 fileName 参数只在 Linux 和 Windows 系统中提供,因此你应该准备好相应的回退机制以防止它是 undefined。
文件操作
基本操作
- 文件读取:fs.readFile / fs.readFileSync
- 文件写入:fs.writeFile / fs.writeFileSync
- 文件追加:fs.appendFile
- 文件拷贝:fs.copyFile
- 文件删除:fs.unlink
指定位置读写文件操作(高级文件操作)
- 文件打开:fs.open
- 文件读取:fs.read
- 文件写入:fs.write
- 同步磁盘缓存:fs.fsync
- 文件关闭:fs.close
目录操作
- 创建目录:fs.mkdir
- 删除目录:fs.rmdir
- 读取目录内容:fs.readdir
- 查看目录文件信息:fs.stat
- 是否常规文件:stats.isFile
- 是否文件夹:stats.isDirectory
- 上次被读取的时间:stats.atime(Access Time)
- 属性或内容上次被修改时间:stats.ctime(State Change Time)
- 档案内容上次被修改的时间:stats.mtime(Modified time)
- 移动文件或目录:fs.rename
- 截断文件:fs.ftruncate
- 监视文件或目录:fs.watchFile
- 判断文件访问权限:fs.access
拷贝文件
除了使用 fs 模块提供的 API 实现文件拷贝外,也能通过文件读取和文件写入实现文件拷贝。
const fs = require('fs');const path = require('path');const originFile = path.resolve(__dirname, 'data.txt');fs.readFile(originFile, function (err, data) {if (err) throw err;// 得到文件内容const dataStr = data.toString();// 写入文件const targetFile = path.resolve(__dirname, 'copy.txt');fs.write(targetFile, dataStr, function (err) {if (err) throw err;console.log('拷贝成功!');});});
这里使用 fs.readFile 和 fs.writeFile 实现了一个拷贝函数,实现过程是拷贝文件的数据一次性读取到内存,一次性写入到目标文件中,这种针对小文件还好。
而对于大文件几百 Mb 一次性读写不太现实,因此需要多次读取多次写入,下面使用文件操作的高级方法对大文件和文件大小未知的情况实现文件拷贝。
Stream
使用流去处理文件,最大的好处是在此过程中你可以轻松地加工文件(性能更好)。
const fs = require('fs');const readableStream = fs.createReadStream('originFile.txt');const writableStream = fs.createWriteSteam('destFile.txt');readableStream.pipe(writableStream);
Buffer
function copyFile(src, dest, size = 16 * 1024, callback) {// 打开源文件fs.open(src, 'r', (err, readFd) => {// 打开目标文件fs.open(dest, 'w', (err, writeFd) => {let buf = Buffer.alloc(size);let readed = 0; // 下次读取文件的位置let writed = 0; // 下次写入文件的位置(function next() {// 读取fs.read(readFd, buf, 0, size, readed, (err, bytesRead) => {readed += bytesRead;// 如果都不到内容关闭文件if (!bytesRead) fs.close(readFd, err => console.log('关闭源文件'));// 写入fs.write(writeFd, buf, 0, bytesRead, writed, (err, bytesWritten) => {// 如果没有内容了同步缓存,并关闭文件后执行回调if (!bytesWritten) {fs.fsync(writed, err => {fs.close(writed, err => return !err && callback());});}writed += bytesWritten;// 继续读取、写入next();});});})();});});}
通过上述方法,手动维护下次读取位置和下次写入位置,如果参数 readed 和 writed 的位置传入 null,NodeJS 会自动帮我们维护这两个值。
在 NodeJS 中进行文件操作,多次读取和写入时,一般一次读取数据大小为 64k,写入数据大小为 16k。
压缩文件
// Compress A Fileconst fs = require('fs');const zlib = require('zlib');fs.createReadStream('original.tx.gz').pipe(zlib.createGunzip()).pipe(fs.createWritableStream('original.txt'));
递归创建目录
同步创建目录
const fs = require('fs');const path = require('path');function mkdirRecurSync(dir) {const parts = dir.split(path.sep);for (let i = 1; i <= parts.length; i++) {let parent = parts.slice(0, i).join(path.sep);try {fs.accessSync(parent);} catch (error) {fs.mkdirSync(parent);}}}
异步创建目录
const fs = require('fs');const path = require('path');function mkdirRecurAsync(dir, callback) {let parts = dir.split(path.seq);let i = 1;function next() {if (i > parts.length) {return callback && callback();}let parent = parts.slice(0, i++).join(path.sep);fs.access(parent, (err) => {if (err) {fs.mkdir(parent, next);} else {}});}}
Async + Await 创建目录
const fs = require('fs')const path = require('path')async function mkdir(parent) {return new Promise((resolve, reject) => {fs.mkdir(parent, err => {if (err) reject(err)else resolve()})})}async function access(parent) {return new Promise((resolve, reject) => {fs.access(parent, err => {if (err) reject(err)else resolve()})})}async function mkdirPromise(dir, callback) {let parts = dir.split(path.sep);for (let i = 1;i <= parts.length; i++) {let parent = parts.slice(0, i).join(path.sep);try {await access(parent);} else {await mkdir(parent);}}}
递归删除目录
同步删除目录(深度优先)
const fs = require('fs');const path = require('path');function rmDfsSync(dir) {try {let stat = fs.statSync(dir);if (stat.isFile()) {fs.unlinkSync(dir);} else {let files = fs.readdirSync(dir);files.map((file) => path.join(dir, file)).forEach((item) => rmDfsSync(item));fs.rmdirSync(dir);}} catch (e) {console.log('删除失败!');}}
异步删除非空目录(Promise)
const fs = require('fs');const path = require('path');function rmPromise(dir) {return new Promise((resolve, reject) => {fs.tat(dir, (err, stat) => {if (err) return reject(err);if (stat.isDirectory()) {fs.readdir(dir, (err, files) => {let paths = files.map((file) => path.join(dir, file));let promises = paths.map((p) => rmPromise(p));Promise.all(promises).then(() => fs.rmdir(dir, resolve));});} else {fs.unlink(dir, resolve);}});});}rmPromise(path.join(__dirname, 'foo')).then(() => {console.log('Success delete!');});
异步串行删除目录(深度优先)
const fs = require('fs');const path = require('path');function rmDfsAsyncSeries(dir, callback) {setTimeout(() => {fs.stat(dir, (err, stat) => {if (err) return callback(err);if (stat.isDirectory()) {fs.readdir(dir, (err, files) => {let paths = files.map((file) => path.join(dir, file));function next(index) {if (index >= files.length) return fs.rmDir(dir, callback);let current = paths[index];rmDfsAsyncSeries(current, () => next(index + 1));}next(0);});} else {fs.unlink(dir, callback);}});}, 1000);}console.time('COST');rmsAsyncSeries(path.join(__dirname, 'foo'), (err) => {console.timeEnd('COST');});
异步并行删除目录(深度优先)
const fs = require('fs');const path = require('path');function rmDfsAsyncParallel(dir, callback) {setTimeout(() => {fs.stat(dir, (err, stat) => {if (err) return callback(err);if (stat.isDirectory()) {fs.readdir(dir, (err, files) => {let paths = files.map((file) => path.join(dir, file));if (paths.length > 0) {let i = 0;function done() {if (++i === paths.length) {fs.rmdir(dir, callback);}}paths.forEach((p) => rmDfsAsyncParallel(p, done));} else {fs.rmdir(dir, callback);}});} else {fs.unlink(dir, callback);}});}, 1000);}console.time('COST');rmDfsAsyncParallel(path.join(__dirname, 'foo'), (err) => {console.timeEnd('COST');});
同步删除目录(广度优先)
const fs = require('fs');const path = require('path');function rmBfsSync(dir) {let arr = [dir];let index = 0;while (arr[index]) {let current = arr[index++];let stat = fs.statSync(current);if (stat.isDirectory()) {let dirs = fs.readdirSync(current);arr = [...arr, ...dir.map((d) => path.join(current, d))];}}let item;while (null !== (item = arr.pop())) {let stat = fs.statSync(item);if (stat.isDirectory()) {fs.rmdirSync(item);} else {fs.unlinkSync(item);}}}
异步删除目录(广度优先)
function rmBfsAsync(dir, callback) {let dirs = [dir];let index = 0;function rmdir() {let current = dirs.pop();if (current) {fs.stat(current, (err, stat) => {if (stat.isDirectory()) {fs.rmdir(current, rmdir);} else {fs.unlink(current, rmdir);}});}}!(function next() {let current = dirs[index++];if (current) {fs.stat(current, (err, stat) => {if (err) callback(err);if (stat.isDirectory()) {fs.readdir(current, (err, files) => {dirs = [...dirs, ...files.map((item) => path.join(current, item))];next();});} else {next();}});} else {rmdir();}})();}
遍历算法
- 目录是一个树状结构,在遍历时一般使用深度优先+先序遍历算法
- 深度优先,意味着到达一个节点后,首先接着遍历子节点而不是邻居节点
- 先序遍历,意味着首次到达了某节点就算遍历完成,而不是最后一次返回某节点才算数
- 因此使用这种遍历方式时,下边这棵树的遍历顺序时 A > B > D > E > C > F
A/ \B C/ \ \D E F
同步深度优先
const fs = require('fs');const path = require('path');function dfsSync(dir) {fs.readdirSync(dir).forEach((file) => {let child = path.join(dir, file);let stat = fs.statSync(child);if (stat.isDirectory()) {dfsSync(child);} else {console.log(child);}});}
异步深度优先
const fs = require('fs');const path = require('path');function dfsAsync(dir, callback) {fs.readdir(dir, (err, files) => {!(function next(index) {if (index === files.length) {return callback();}let child = path.join(dir, files[index]);fs.stat(child, (err, stat) => {if (stat.isDirectory()) {dfsAsync(child, () => next(index + 1));} else {console.log(child);next(index + 1);}});})(0);});}
同步广度优先
const fs = require('fs');const path = require('path');function bfsSync(dir) {let dirs = [dir];while (dirs.length > 0) {let current = dirs.shift();let stat = fs.statSync(current);if (stat.isDirectory()) {let files = fs.readdirSync(current);files.forEach((item) => {dirs.push(path.join(current, item));});}}}
异步广度优先
const fs = require('fs');const path = require('path');function bfsAsync(dir, cb) {cb && cb();fs.readdir(dir, (err, files) => {!function next(i) {if (i >= files.length) return;let child = path.join(dir, files[i]);fs.stat(child, (err, stat) => {if (stat.isDirectory()) {bfsAsync(child, () => next(i + 1));} else {next(i + 1);}});};});}