构建对象模型
浏览器渲染页面前需要先构建 DOM 树和 CSSOM 树。而 DOM 树 和 CSSOM 树是基于 HTML 文件和 CSS 文件构建的。
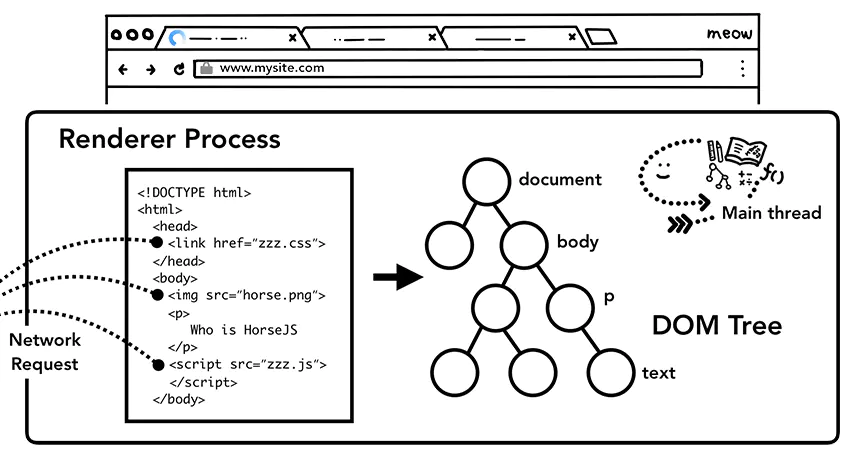
文档对象模型
文档对象模型的构建过程。
字节(Bytes) => 字符(Characters) => 令牌(Tokens) => 节点(Nodes) => 文档对象模型(DOM)
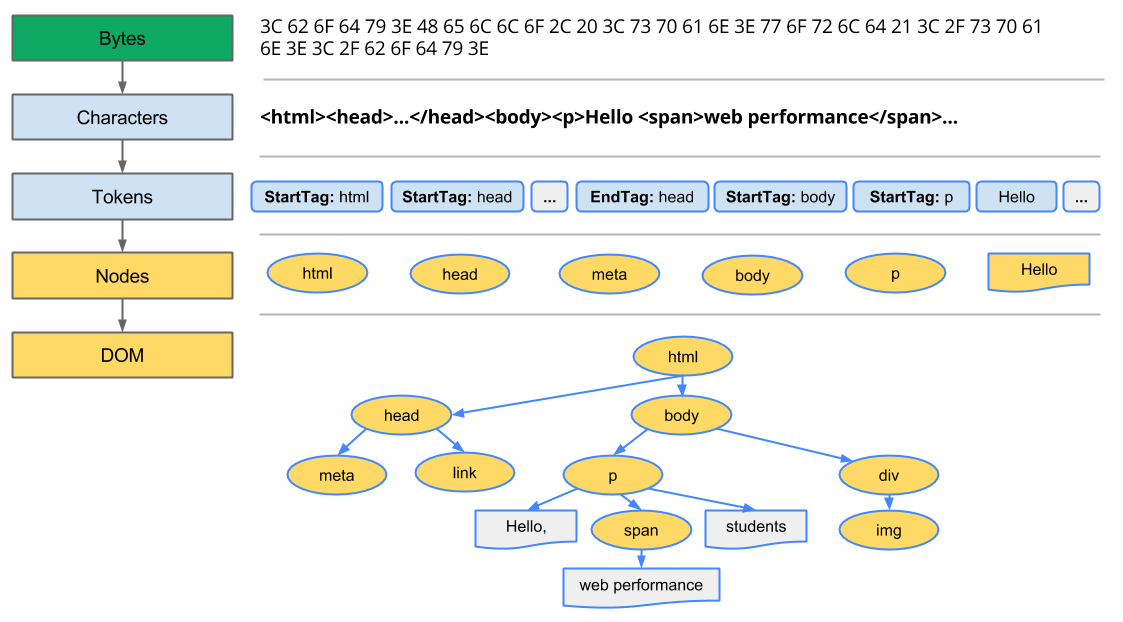
- 转换: 浏览器从磁盘或网络读取 HTML 的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符。
- 令牌化: 浏览器将字符串转换成 W3C HTML5 标准 规定的各种令牌,例如,
<html>、<body>,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则。 - 词法分析: 发出的令牌转换成定义其属性和规则的"对象"。
- DOM 构建: 最后,由于 HTML 标记定义不同标记之间的关系(一些标记包含在其他标记内),创建的对象链接在一个树数据结构内,此结构也会捕获原始标记中定义的父项-子项关系:HTML 对象是
body对象的父项,body是paragraph对象的父项,依此类推。
整个流程的最终输出是我们这个简单页面的文档对象模型 (DOM),浏览器对页面进行的所有进一步处理都会用到它。
浏览器每次处理 HTML 标记时,都会完成以上所有步骤:将字节转换成字符,确定令牌,将令牌转换成节点,然后构建 DOM 树。这整个流程可能需要一些时间才能完成,有大量 HTML 需要处理时更是如此。
CSS 对象模型
与处理 HTML 时一样,我们需要将收到的 CSS 规则转换成某种浏览器能够理解和处理的东西。因此,我们会重复 HTML 过程,不过是为 CSS 而不是 HTML:
字节(Bytes) => 字符(Characters) => 令牌(Tokens) => 节点(Nodes) => CSS 对象模型(CSSOM)
CSS 字节转换成字符,接着转换成令牌和节点,最后链接到一个称为 CSS 对象模型(CSSOM)的树结构内:
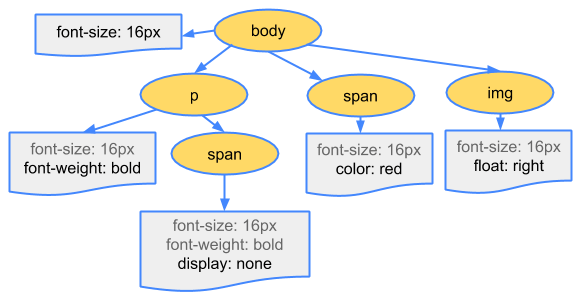
CSSOM 为何具有树结构?为页面上的任何对象计算最后一组样式时,浏览器都会先从适用于该节点的最通用规则开始(例如,如果该节点是 body 元素的子项,则应用所有 body 样式),然后通过应用更具体的规则(即规则向下级联)以递归方式优化计算的样式。
还请注意,以上树并非完整的 CSSOM 树,它只显示了我们决定在样式表中替换的样式。每款浏览器都提供一组默认样式(也称为 User Agent 样式),即我们不提供任何自定义样式时所看到的样式,我们的样式只是替换这些默认样式(例如 默认 IE 样式)。