文件应用
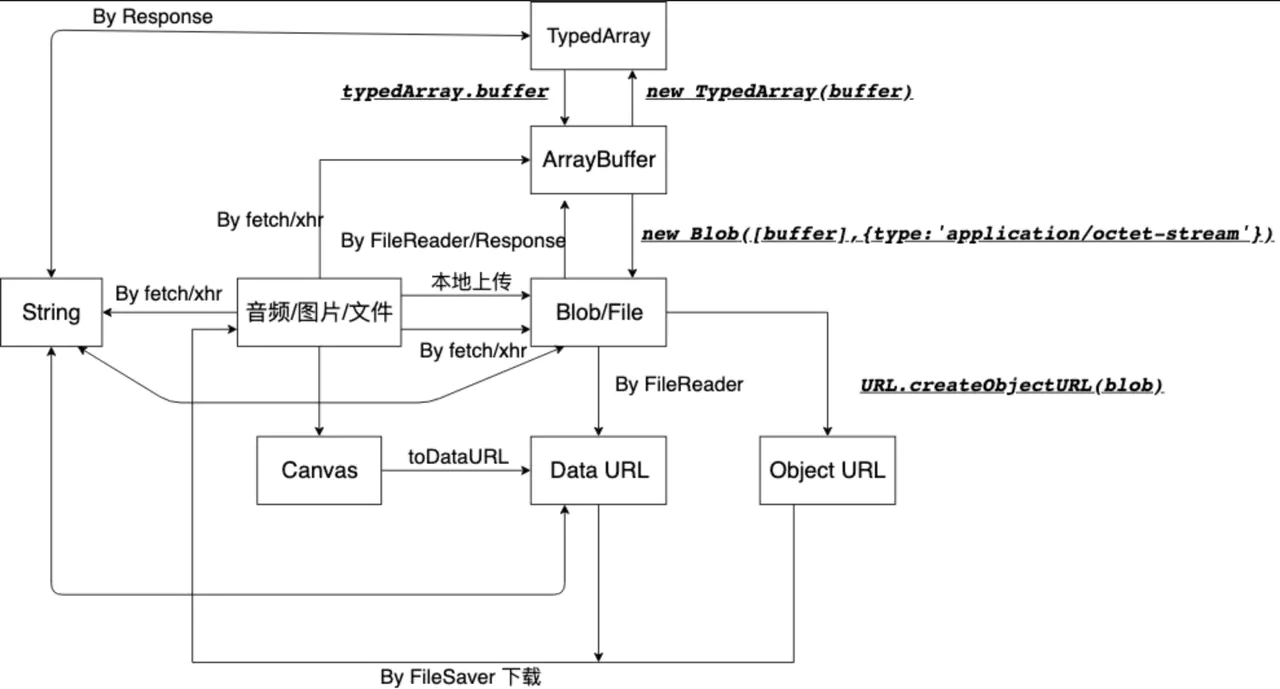
历史上,JavaScript 无法处理二进制数据。如果一定要处理的话,只能使用 String.prototype.charCodeAt() 方法,逐个地将字节从文字编码转成二进制数据,还有一种办法是将二进制数据转成 Base64 编码,再进行处理。这两种方法不仅速度慢,而且容易出错。因此 ECMAScript 5 引入了 Blob 对象,允许直接操作二进制数据。
- Blob 对象:二进制数据基本对象,在它的基础上,又衍生出一系列相关的 API,用于操作文件
- File 对象:负责处理那些以文件形式存在的二进制数据,也就是操作本地文件
- FileList 对象:File 对象的网页表单接口
- FileReader 对象:负责将二进制数据读入内存内容
- URL 对象:用于对二进制数据生成 URL
- FormData 对象:读取页面表单项文件数据
文件上传结构
FormData
File API 使访问包含 File 对象的 FileList 成为可能,FileList 代表被用户选择的文件列表。
如果用户只选择了一个文件,那么只需要考虑 FileList 中的第一个 File 对象。
<!-- 只可以选择单个文件 --><input id="single" type="file" /><!-- 可选择多个文件 --><input id="multipart" /><script type="text/javascript">const input = document.querySelector('#single');// 监听表单输入框的 `change` 事件访问 FileListinput.addEventListener('change',function(e) {handleFiles(e.target.files);},false);// 监听 document 的 `dragover` 和 `drop` 事件通过拖拽选择文件document.addEventListener('dragover',function(e) {e.preventDefault();e.stopPropagation();},false);document.addEventListener('drop',function(e) {e.preventDefault();e.stopPropagation();handleFiles(e.dataTransfer.files);},false);function handleFiles(files) {const fileReader = new FileReader();form.append('file', files[0]);axios.post('https://localhost:8080/upload', form).then(res => console.log(res));}</script>
大文件上传
实现思路
对于大文件上传考虑到上传时间太久、超出浏览器响应时间、提高上传效率、优化上传用户体验等问题进行了深入探讨,以下初略罗列各个知识点的实现思路:
- 大文件上传对文件本身进行了文件流内容 Blob 的分割,使用
Blob.prototype.slice实现大文件的上传切分为多个小文件的上传 - 为了实现大文件上传能否做到秒传、辨别是否已存在、文件切片的秒传等功能,需要对大文件进行计算 Hash 的唯一标识,通过使用 WebWorker 开启浏览器线程来计算文件 Hash,防止阻塞 UI 渲染(另外也采用 React Fiber 所用的时间分片思想方式
requestIdleCallbackAPI 来计算) - 上传暂停/恢复功能采用 XMLHttpRequest 请求带有的
abort方法进行请求的取消来实现 - 判断文件是否已存在,在性能上可以通过计算抽样 Hash 来大大缩短大文件全量计算 Hash 的时间,使用这个抽样 Hash 向服务器确认是否已存在文件,而达到秒传的功能,抽样 Hash 的作用在于牺牲一点点的识别率来换取时间
- 大文件切分为小文件后,通过设置一个上传通道限制,实现控制并发上传数来防止一次性过多的 HTTP 请求而卡死浏览器
- 文件切片上传采用请求
catch捕获方式,来对上传失败的内容进行重试,重试三次后再失败就进行放弃 - 对文件服务器过期的文件切片开启定时器清理,采用了
node-schedule来实现
上传切片
<!-- 单选文件 --><input id="fileInput" type="file" />
const fileInput = document.querySelector('#fileInput');// 1. 点击输入框选择文件后触发fileInput.addEventListener('change', e => {const [file] = e.target.files;if (!file) return;const chunkList = sliceFileChunk(file);});// 2. 文件切片function sliceFileChunk(file) {// 文件大小const FILE_SIZE = file.size;// 文件切片大小const CHUNK_SIZE = 2 * 1024 * 1024;// 切片的个数const CHUNKS = Math.ceil(FILE_SIZE / CHUNK_SIZE);const blobSlice = Fil.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;// 生成 MD5const spark = new SparkMD5.ArrayBuffer();// 实例化读取文件对象const reader = new FileReader();const currentChunk = 0;reader.onload = function(e) {const resul = e.target.result;spark.append(result);currentChunk++;if (currentChunk < chunks) {loadNext();console.log(`第${currentChunk}个分片解析完成`);} else {const md5 = spark.end();console.log('解析完成');}};function loadNext() {const start = currentChunk * CHUNK_SIZE;const end = start + CHUNK_SIZE > file.size ? file.size : start + CHUNK_SIZE;reader.raedAsArrayBuffer(blobSlice.call(file, start, end));}loadNext();}// 上传切片async function uploadChunkus() {const requestList = this.data.map(({ chunk, hash }) => {const formData = new FormData();formData.append('chunk', chunk);formData.append('hash', hash);formData.append('filename', this.container.file.name);return { formData };}).map(async ({ formData }) => {return this.request({url: 'http://localhost:3000',data: formData,});});// 并发上传文件切片await Promise.all(requestList);}async function handleUpload() {}
发送合并请求
接受切片
const http = require('http');const path = require('path');const fse = require('fs-extra');const multiparty = require('multiparty');const server = http.createServer();// 大文件存储目录const UPLOAD_DIR = path.resolve(__dirname, '..', 'target');server.on('request', async (req, res) => {res.setHeader('Access-Control-Allow-Oriign', '*');res.setHeader('Access-Control-Allow-Headers', '*');if (req.method === 'OPTIONS') {res.status = 200;res.end();return;}const multipart = new multiparty.Form();multipart.parse(req, async (err, fields, files) => {if (err) return;const [chunk] = files.chunk;const [hash] = fields.hash;const [filename] = fields.filename;const chunkDir = path.resolve(UPLOAD_DIR, filename);// 切片目录不存在,创建切片目录if (!fse.existsSync(chunkDir)) {await fse.mkdirs(chunkDir);}// fs-extra 专用方法,类似 fs.rename 并且跨平台// fs-extra 的 rename 方法 windows 平台会有权限问题await fse.move(chunk.path, `${chunkDir}/${hash}`);res.end('Received file chunk');});});server.listen(3000, () => console.log('Server is listening port 3000.'));
合并切片
由于前端在发送合并请求时会携带文件名,服务端根据文件名可以找到上一步创建的切片文件夹。
接着使用 fs.createWriteStream 创建一个可写流,可写流文件名就是 切片文件夹名 + 后缀名 组合而成。
随后遍历整个切片文件夹,将切片通过 fs.createReadStream 创建可读流,传输合并到目标文件中。
值得注意的是每次可读流都会传输到可写流的指定位置,这是通过 createWriteStream 的第二个参数 start/end 控制的,目的是能够并发合并多个可读流到可写流中,这样即使流的顺序不同也能传输到正确的位置,所以这里还需要让前端在请求的时候多提供一个 size 参数。
断点续传
断点续传的原理在于前端/服务端需要 记住 已上传的切片,这样下次上传就可以跳过之前已上传的部分,有两种方案实现记忆的功能:
- 前端使用
localStorage记录已上传的切片hash - 服务端保存已上传的切片
hash,前端每次上传前向服务端获取已上传的切片
生成标识
无论是前端还是服务端,都必须要生成文件和切片的 Hash,之前我们使用 文件名 + 切片下标 作为切片 Hash,这样做文件名一旦修改就失去了效果,而事实上只要文件内容不变,Hash 就不应该变化,所以正确的做法是根据文件内容生成 hash,所以我们修改一下 Hash 的生成规则。
文件秒传
暂停上传
恢复上传
进度条改进
参考资料: