- 应用场景
- 技术架构
- 基本概念
- 文档
- 元数据
- 索引
- 类型
- 节点
- 分片
- 倒排索引
- Analyzer 分词
- 搜索 API
- URL 查询
- Request Body 查询
- Dynamic Mapping
- 如何写 Mapping
- Aggregation 聚合分析
- Bucket 分析示例
- Metric 分析示例
Elasticsearch
ElasticSearch 是一个分布式搜索服务,提供的是一组 Restful API,底层基于 Lucene,采用多 shard(分片)的方式保证数据安全,并且提供自动 resharding 的功能。是目前全文搜索引擎的首选,可以快速的存储、搜索和分析海量数据,Springboot 通过整合 Spring Data ElasticSearch 为我们提供了非常方便的检索功能支持。
应用场景
- 网站搜索、代码搜索等(例如生产环境的日志收集——格式化分析——全文检索——系统预警)
- 日志管理与分析、应用系统性能分析、安全指标监控等
技术架构
Elastic static 家族产品
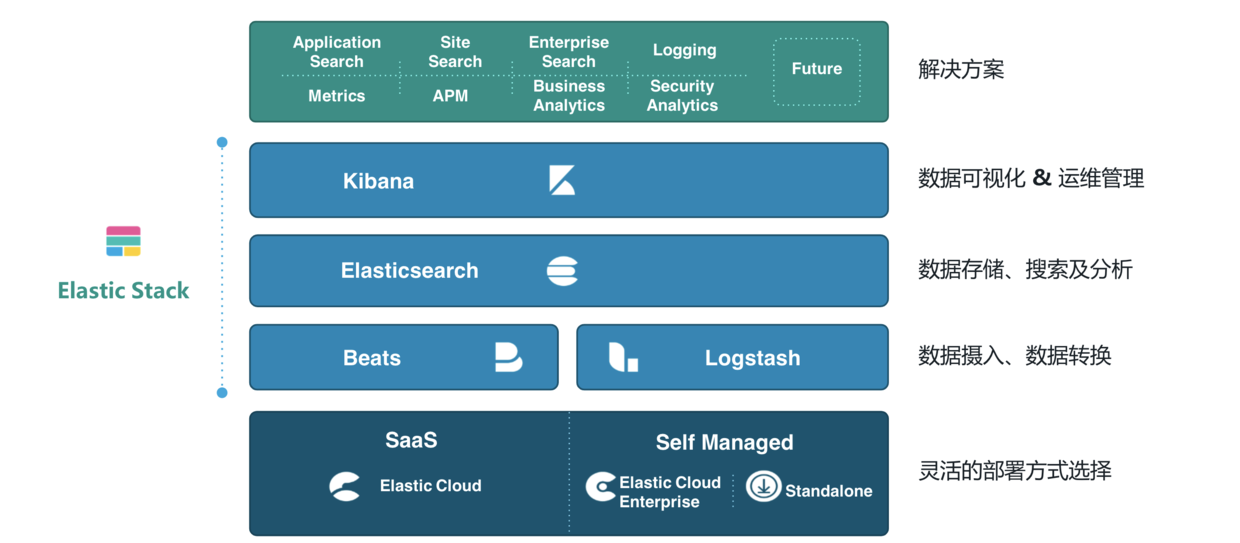
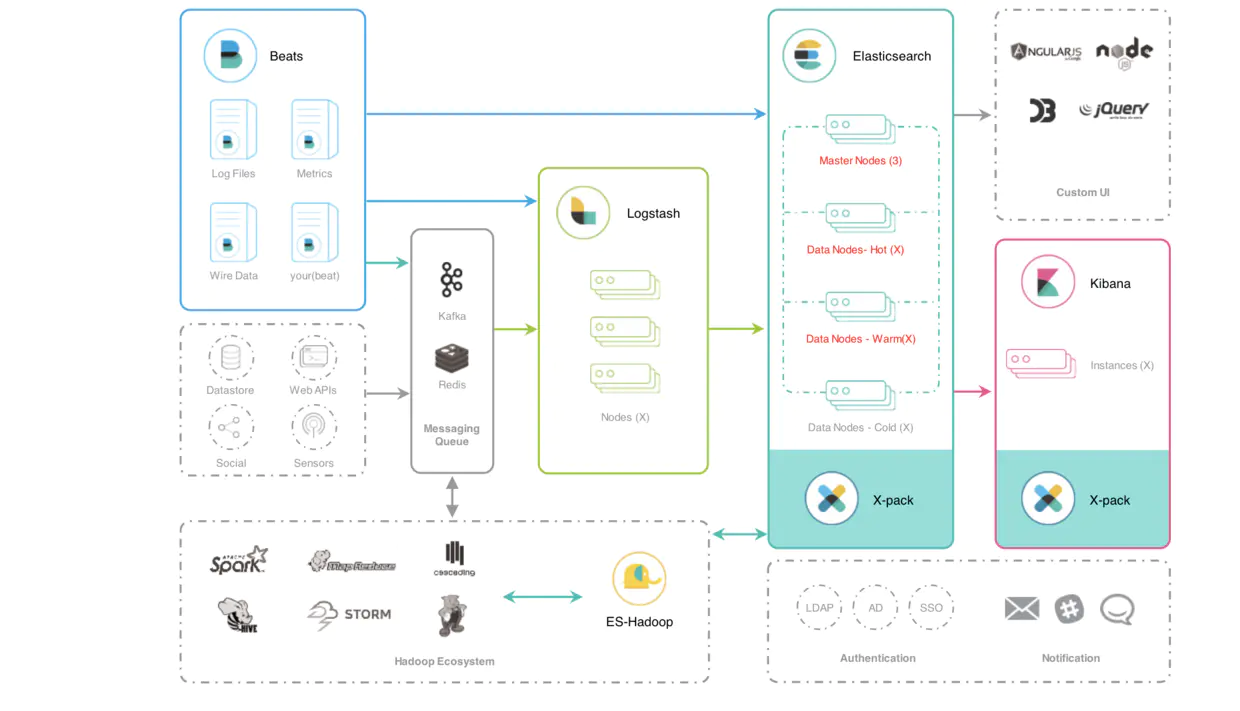
Elastic 的技术架构可以简单,也可以高级,它是很具有扩展性的,最简单的技术架构就是使用 Beats 进行数据的收集,Beats 是一种抽象的称呼,具体的可以是使用 FileBeat 收集数据源为文件的数据或者使用 TopBeat 来收集系统中的监控信息,可以说类似 Linux 系统中的 TOP 命令,当然还有很多的 Beats 的具体实现,再使用 Logstash 进行数据的转换和导入到 Elasticsearch 中,最后使用 Kibana 进行数据的操作以及数据的可视化等操作。
当然,在生产环境中,我们的数据可能在不同的地方,例如关系型数据库 Postgre,或者 MQ,再或者 Redis 中,我们可以统一使用 Logstash 进行数据的转换,同时,也可以根据数据的热度不同将 ES 集群架构为一种冷温热架构,利用 ES 的多节点,将一天以内的数据称谓热数据,读写频繁,就存放在 ES 的热节点中,七天以内的数据称之为温数据,就是偶尔使用的数据存放在温节点中,将极少数会用到的数据存放在冷节点中。
基本概念
文档
Elasticsearch 面向文档性,文档就是所有可搜索数据的最小单位。比如,一篇 PDF 中的内容,一部电影的内容,一首歌等,文档会被序列化成 JSON 格式,保存在 Elasticsearch 中,必不可少的是每个文档都会有自己的唯一标识,可以自己指定,也可以由 Elasticsearch 帮你生成。类似数据库的一行数据。
元数据
{"_index": "user","_type": "_doc","_id": "l0D6UmwBn8Enzbv1XLz0","_score": 1.6943597,"_source": {"user": "mj","sex": "男","age": "18"}}
_index:文档所属的索引名称_type:文档所属的类型名_id:文档的唯一标识_version:文档的版本信息_score:文档的相关性打分_source:文档的原始 JSON 内容
索引
索引 是文档的容器,是一类文档的集合,类似关系数据库中的表,索引体现的是一种逻辑空间的概念,每个索引都应该有自己的 Mapping 定义,用于定义包含文档的字段名和字段类型。其中 Shard(分片)体现的是物理空间的一种概念,就是索引中的数据存放在 Shard 上,因为有集群,要保证高可用,当其中一个机器崩溃中,保存在它上的分片数据也能被正常访问,因此,存在分片副本。
索引 中有两个重要的概念,Mapping 和 Setting。
Mapping定义的是文档字段和字段类型Setting定义的是数据的不同分布
类型
在 7.0 之前,一个 index 可以创建多个类型 Type。之后就只能一个 index 对应一个类型 Type。
节点
一个节点就是一个 Elaseticsearch 实例,本质就是一个 Java 进程。每一个节点启动后,默认就是一个 master eligible 节点。就是具备成为 master 资格的节点,你也可以狠心的指定它没有这个资格(node.master: false), 第一个节点启动后,他就选自己成为 Master 节点类,每一个节点上都保存了集群状态,但是,只有 Master 才能修改集群状态信息。集群状态信息就比如:
- 所有的节点信息
- 所有的索引信息,索引对应的
mapping信息和setting信息 - 分片的路由信息
分片
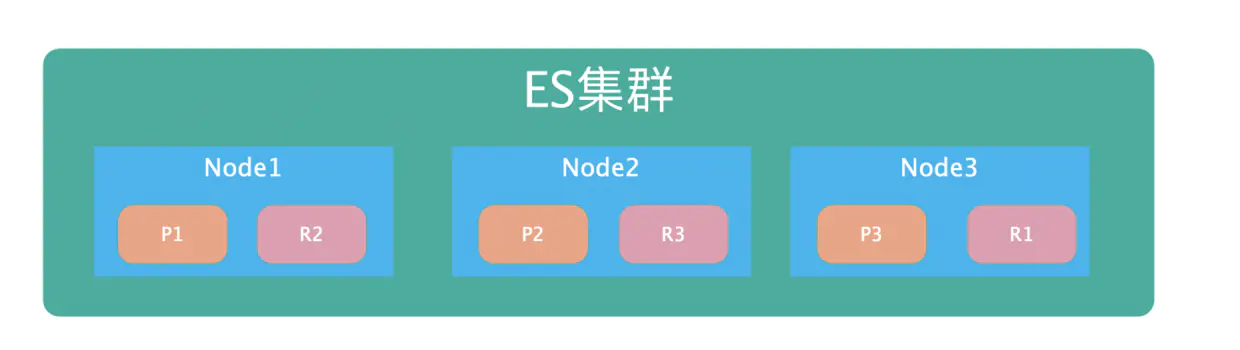
- 主分片:用于解决数据的水平扩展问题,通过主分片就数据分布在集群内的不同节点上,主分片在创建索引的时候就指定了,后面就不允许修改,除非重新定义
Index - 副本:用于解决高可用的问题,分片是主分片的拷贝。副本分片数可以动态的调整,增加副本数量可以在一定的程度上提高服务的可用性。关于主分片的理解可以如下图,看是怎样实现高可用的
{"settings": {"index": {// 设置主分片数"number_of_shards": "1","auto_expand_replicas": "0-1","provided_name": "kibana_sample_data_logs","creation_date": "1564753951554",// 设置副本分片数"number_of_replicas": "1","uuid": "VVMLRyw6TZeSfUvvLNYXEw","version": {"created": "7010099"}}}}
倒排索引
正排索引:就是文档 ID 到文档内容的索引,简单讲,就是根据 ID 找文档。
倒排索引:就是根据文档内容找文档。
倒排索引包含如下信息:
- 单词词典:用于记录所有文档的单词,以及单词到倒排列表的关联关系。
- 倒排列表:记录的是单词对应的文档集合,由倒排索引项组成,其中包含
- 文档 ID
- 单词出现的次数,用于相关性的评分
- 单词出现的位置
- 偏移量,用于记录单词的开始位置和结束位置,用于单词的高亮显示
举例说明什么是正排索引和倒排索引,其中正排索引如下:
| 文档 ID | 文档内容 |
|---|---|
| 1101 | Elasticsearch Study |
| 1102 | Elasticsearch Server |
| 1103 | master Elasticsearch |
讲上例 Elasticsearch 单词修改为倒排索引,如下:
| 文档 ID | 出现次数 | 位置 | 偏移量 |
|---|---|---|---|
| 1101 | 1 | 0 | <0,13> |
| 1102 | 1 | 0 | <0,13> |
| 1103 | 1 | 1 | <7,20> |
Elasticsearch 中的每一个字段都有自己的倒排索引,也可以指定某些字段不做索引,可以节省存储空间,缺点就是不能被搜索到。
Analyzer 分词
Analysis:文本分析,就是将文本转换为单词(term 或者 token)的过程,其中 Analyzer 就是通过 Analysis 实现的,Elasticsearch 给我们内置例很多分词器。
Standard Analyzer:默认的分词器,按照词切分,并作大写转小写处理Simple Analyzer:按照非字母切分(符号被过滤),并作大写转小写处理Stop Anayzer:停用词(the、is)切分,并作大写转小写处理Whitespace Anayzer:空格切分,不做大写转小写处理IK:中文分词器,需要插件安装ICU:国际化的分词器,需要插件安装jieba:时下流行的一个中文分词器。安装方法见附录
PS:Elasticsearch 安装插件,
[root@34d02ff9d16c elasticsearch]# bin/elasticsearch-plugin install analysis-icu查看已经安装的插件:bin/elasticsearch-plugin list
搜索 API
在 ES 中,我们可以使用 URL Search 和 Request Body Search 进行相关的查询操作。
URL 查询
使用基本的查询
GET /user/_search?q=2012&df=title&sort=year:desc&from=0&size=10{"profile": true}
- 使用
q指定查询的字符串 - 使用
df指定查询的字段 - 使用
sort进行排序,使用from和size指定分页 - 使用
profile可以查询查询是如何进行查询的
指定所有字段的泛查询
GET /user/_search?q=2012{"profile":"true"}
指定字段的查询
GET /user/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s{"profile":"true"}
Term 查询
GET /user/_search?q=title:Beautiful Mind{"profile":"true"}
- 上例的
Beautiful和Mind就是两个Term,Term是查询中最小的单位 Term查询是OR的关系,在上例中就是title字段包含Beautiful或者包含Mind都会被检索到
Phrase 查询
GET /user/_search?q=title:"Beautiful Mind"{"profile":"true"}
- 使用引号表示
Phrase查询 Phrase查询表示的不仅是And的关系,即Title字段中不仅要包含Beautiful Mind,而且。顺序还要一致。
分组查询
GET /user/_search?q=title:(Beautiful Mind){"profile":"true"}
- 使用中括号表示分组查询,一般使用
Term查询的时候都会带上分组查询
布尔查询:
- 使用
AND、OR、NOT或者||、&&、! - 还可以是哟功能
+(表示must),使用-(表示must_not) - 需要注意的是必须大写
GET /user/_search?q=title:(Beautiful NOT Mind){"profile":"true"}
GET /user/_search?q=title:(Beautiful %2BMind){"profile":"true"}
PS:
%2B表示的就是+,上例子表示的就是title字段中既要包含Beautiful,也要包含Mind字段
范围查询:
GET /user/_search?q=title:beautiful AND age:[2002 TO 2018%7D{"profile":"true"}
- 使用
[ ]表示闭区间,使用{ }表示区间,例如age: [* TO 56] - 使用算术符表示范围,例如
year: >= 2019 && <= 1970
PS:
URL Search还有很多查询方式。例如通配符查询,正则插叙,模糊匹配,相似查询,其中通配符查询不建议使用。
Request Body 查询
将查询的条件参数放在 Request Body 中,调用查询接口,就是 Request Body 查询,
基本的查询
POST /movies,404_idx/_search?ignore_unavailable=true{"profile": true,"query": {"match_all": {}}}
- 使用
gnore_unavailable=true可以避免索引404_idx不存在导致的报错 profile和URL Search查询一样,可以看到查询的执行方式
分页查询
POST /movies/_search{"from":10,"size":20,"query":{"match_all": {}}}
排序查询
POST /movies/_search{"sort":[{"order_date":"desc"}],"query":{"match_all": {}}}
过滤要查询的字段
POST /movies/_search{"_source":["order_date"],"query":{"match_all": {}}}
- 如果一个文档中的字段太多,我们不需全部字段显示,就可以使用
_source指定字段。可以使用通配符
使用脚本查询
将 ES 中的文档字段进行一定的处理后,再根据这个新的字段进行排序
GET /movies/_search{"script_fields": {"new_field": {"script": {"lang": "painless","source": "doc['name'].value+'是大佬'"}}},"query": {"match_all": {}}}
Term 查询
POST /movies/_search{"query": {"match": {"title": "last christmas"}}}POST movies/_search{"query": {"match": {"title": {"query": "last christmas","operator": "and"}}}}
- 使用
match,表示的就是OR的关系 - 使用
operator,表示查询方式
Math_Phrase 查询
POST movies/_search{"query": {"match_phrase": {"title":{"query": "one love","slop": 4}}}}
slop指定查询的字符中允许出现的字符
Dynamic Mapping
Mapping 可以简单的理解为数据库中的 Schema 定义,用于定义索引中的字段的名称,定义字段的类型,字段的倒排索引,指定字段使用何种分词器等。Dynamic Mapping 意思就是在我们创建文档的时候,如果索引不存在,就会自动的创建索引,同时自动的创建 Mapping,ElasticSearch 会自动的帮我们推算出字段的类型,当然,也会存在推算不准确的时候,就需要我们手动的设置。
常用的字段类型如下:
- 简单类型:Text、Date、Integer、Boolean 等
- 复杂类型:对象类型和嵌套类型。
我们可以使用 GET /shgx/_mapping 查询索引的 Mapping 的设置,需要注意的是以下几点:
- 当我们对索引中的文档新增字段时候,希望可以更新索引的 Mapping 就可以可以设置 Dynamic:true。
- 对于已经有数据的字段,就不再允许修改其 Mapping,因为 Lucene 生成的倒排索引后就不允许修改。
Dynamic Mapping 可以设置三个值,分别是:
true:文档可被索引,新增字段也可被索引,Mapping 也会被更新。false:文档可被索引,新增字段不能被索引,Mapping 不会被更新。strict:新增字段写入,直接报错。
如何写 Mapping
第一种方式是参考官方 API,纯手工写,也可以先创建一个临时的 Index 让 ElasticSearch 自动当我们推断出基本的 Mapping,然后自己在改吧改吧,最后把临时索引删掉就是啦。下面列举一些常用的 Mapping 设置属性:
index:可以设置改字段是否需要被索引到。设置为false就不会生成倒排索引,节省啦磁盘开销null_value:可以控制 NULL 是否可以被索引cope_to:将字段值放在一个新的字段中,可以使用新的字段search,但这个字段不会出现在_source中。anaylzer:指定字段的分词器search_anaylzer:指定索引使用的分词器index_options:控制倒排索引的生成结构,有四种情况docs:倒排索引只记录文档 IDfreqs:记录文档 ID 和Termpositions:记录文档 ID、Term 和Term Positionoffsets:记录文档 ID、Term、Term Position和offsets
Aggregation 聚合分析
ElasticSearch 不仅仅是搜索强大,他的统计功能也是相当的强大的,聚合分析就是统计整个数据的一个分类数量等,例如武侯区有多少新楼盘。天府新区有多少新楼盘,通过聚合分析我们只需要写一条语句就可以得到。在加上 Kibana 的可视化分析,简直就是清晰,高效。常用的集合有以下几种:
Bucket Aggregation:满足特定条件的一些集合,使用关键字termsMetric Aggregation:简单的数学运算,对字段进行统计分析,使用关键字min、max、sum、avg等,使用关键字aggsPipeline Aggregation:二次聚合Matrix Aggregation:对多个字段进行操作,提供一个结果矩阵
Bucket 分析示例
GET kibana_sample_data_flights/_search{"size": 0,"aggs":{"flight_dest":{"terms":{"field":"DestCountry"}}}}
Metric 分析示例
GET kibana_sample_data_flights/_search{"size": 0,"aggs":{"flight_dest":{"terms":{"field":"DestCountry"},"aggs":{"avg_price":{"avg":{"field":"AvgTicketPrice"}},"max_price":{"max":{"field":"AvgTicketPrice"}},"min_price":{"min":{"field":"AvgTicketPrice"}}}}}}
参考资料: