PM2
PM2 是常用的 Node 进程管理工具,它可以提供 node.js 应用管理,如自动重载、性能监控、负载均衡等。同类工具有 Supervisor、Forever 等。
重要特性
- 内建负载均衡(使用 Node Cluster 集群模块、子进程)
- 线程守护,Keep Alive
- 0 秒停机重载,维护升级的时候不需要停机
- Linux(Stable)& MacOSx(Stable)& Windows(Stable)多平台支持
- 停止不稳定的进程(避免无限循环)
- 控制台实时检测运行情况
- 提供 HTTP API
- 远程控制和实时的接口 API(Node.js 模块,允许和 PM2 进程管理器交互)
- 模块拓展机制
项目结构
lib├── API # 日志管理、GUI 等辅助功能├── God # 多进程管理逻辑实现位置└── Sysinfo # 系统信息采集
几个关键的文件:
Daemon.js:守护进程的主要逻辑实现,包括 RPC Server,以及各种守护进程的能力God.js:业务进程的包裹层,负责与守护进程建立连接,以及注入一些操作,我们编写代码最终是由这里执行的Client.js:执行 PM2 命令的主要逻辑实现,包括与守护进程建立 RPC 连接,以及各种请求守护进程的操作API.js:各种功能的实现,包括启动、关闭项目、展示列表、展示系统信息等操作,会调用 Client 的各种函数binaries/CLI.js:执行 PM2 命令时候触发的入口文件
启动程序的方式
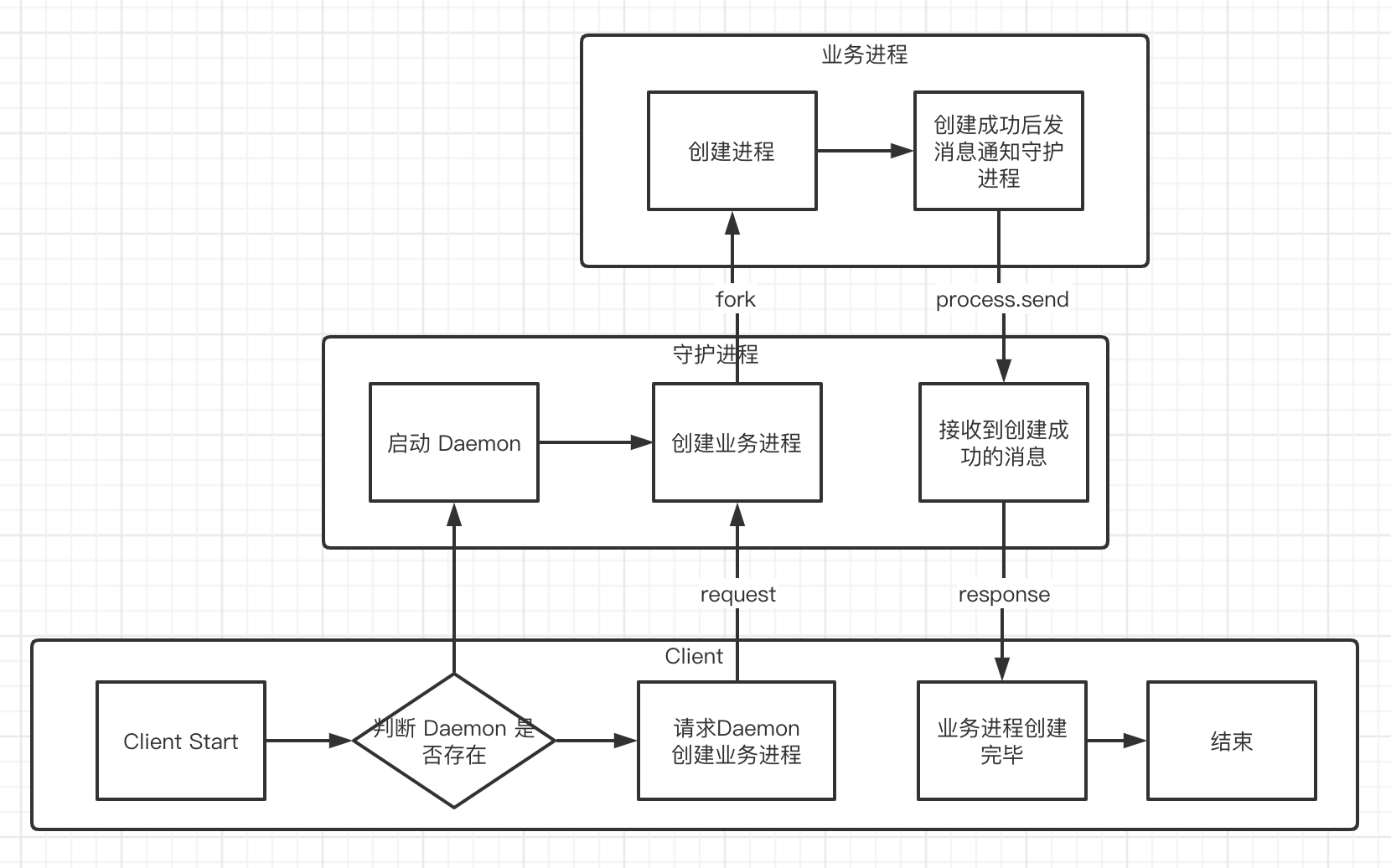
PM2 并不是简单的使用 node XXX 来启动我们的程序,就像前边所提到了守护进程与 Client 进程的通讯方式,Client 进程会将启动业务进程所需要的配置,通过 RPC 传递给守护进程,由守护进程去启动程序。
这样,在 pm2 start 命令执行完成以后业务进程也在后台运行起来了,然后等到我们后续想再针对业务进程进行一些操作的时候,就可以通过列表查看对应的 pid、name 来进行对应的操作,同样是通过 Client 触发 RPC 请求到守护进程,实现逻辑。
当然,我们其实很少会有单独启动守护进程的操作,守护进程的启动其实被写在了 Client 启动的逻辑中,在 Client 启动的时候会检查是否有存活的守护进程,如果没有的话,会尝试启动一个新的守护进程用于后续的使用。
具体方式就是通过 spawn + detached: true 来实现的,创建一个单独的进程,这样即便是我们的 Client 作为父进程退出了,守护进程依然是可以独立运行在后台的。
⚠️ 注意: 在使用 PM2 的时候应该有时也会看到有些这样的输出,这个其实就是 Client 运行时监测到守护进程还没有启动,主动启动了守护进程:
> [PM2] Spawning PM2 daemon with pm2_home=/data/default/.pm2> [PM2] PM2 Successfully daemonized
前置知识
熟悉 JavaScript 的朋友都知道,JavaScript 是单线程的,在 Node.js 中,采用的是 多进程单线程 的模型。由于单线程的限制,在多核服务器上,我们往往需要启动多个进程才能最大化服务器性能。
Node 在 v0.8 版本之后引入了 cluster 模块,通过一个主进程 (master) 管理多个子进程 (worker) 的方式实现集群。
const cluster = require('cluster');const http = require('http');const numCPUs = require('os').cpus().length;if (cluster.isMaster) {console.log(`Master ${process.pid} is running`);// Fork workersfor (let i = 0; i < numCPUs; i++) {cluster.fork();}cluster.on('exit', (worker, code, signal) => {console.log(`worker ${worker.process.pid} died`);});} else {// Wokers can share any TCP connection// In this case it is an HTTP serverhttp.createServer((req, res) => {res.writeHead(200);res.end('Hello world\n');}).listen(8000);console.log(`Worker ${process.pid} started`);}
通讯机制
Node 中主进程和子进程之间通过进程间通信 (IPC) 实现进程间的通信,进程间通过 send 方法发送消息,监听 message 事件收取信息,这是 cluster 模块 通过集成 EventEmitter 实现的。
还是一个简单的官网的进程间通信例子
const cluster = require('cluster');const http = require('http');if (cluster.isMaster) {// Keep track of http requestslet numReqs = 0;setInterval(() => {console.log(`numReqs = ${numReqs}`);}, 1000);// Count requestsfunction messageHandler(msg) {if (msg.cmd && msg.cmd === 'notifyRequest') {numReqs += 1;}}// Start workers and listen for messages containing notifyRequestconst numCPUs = require('os').cpus().length;for (let i = 0; i < numCPUs; i++) {cluster.fork();}for (const id in cluster.workers) {cluster.workers[id].on('message', messageHandler);}} else {// Worker processes have a http server.http.Server((req, res) => {res.writeHead(200);res.end('hello world\n');// Notify master about the requestprocess.send({ cmd: 'notifyRequest' });}).listen(8000);}
负载均衡
了解 cluster 的话会知道,子进程是通过 cluster.fork() 创建的。在 Linux 中,系统原生提供了 fork 方法,那么为什么 Node 选择自己实现 cluster 模块 ,而不是直接使用系统原生的方法?
主要的原因是以下两点:
fork的进程监听同一端口会导致端口占用错误fork的进程之间没有负载均衡,容易导致惊群现象
在 cluster 模块 中,针对第一个问题,通过判断当前进程是否为 master 进程,若是,则监听端口,若不是则表示为 fork 的 worker 进程,不监听端口。
针对第二个问题,cluster 模块 内置了负载均衡功能,master 进程 负责监听端口接收请求,然后通过调度算法(默认为 Round-Robin,可以通过环境变量 NODE_CLUSTER_SCHED_POLICY 修改调度算法)分配给对应的 worker 进程。
模式
fork模式不支持 Socket 地址端口复用,cluster支持地址端口复用fork不支持定时重启,cluster支持定时重启- 为了实现最大的 CPU 资源利用,一般都采用
cluster模式(仅限于 Node.js 应用) fork模式下实现多进程可以是哟功能创建多个应用app0、app1、app2,每个应用映射到不同的端口
参考资料: