HTTP3
HTTP 发展历史
- HTTP/0.9 - 1991 单行协议:只支持 GET 方法;没有首部;只能获取纯文本
- HTTP/1.0 - 1996 搭建协议框架:增加了首部、状态码、权限、缓存、长连接(默认短连接)等规范
- HTTP/1.1 - 1997 默认长连接;缓存字段扩展;强制客户端提供 Host 首部;管线化
- SPDY - 2012 强制压缩、多路复用、Pipeling、双向通信、优先级调用
- HTTP/2 - 2015 头部压缩、多路复用、Pipelining、Server push(解决 HTTP 队首阻塞)
- HTTP/3 - 2018 快速握手、可靠传输、有序交付(解决 TCP 队首阻塞)
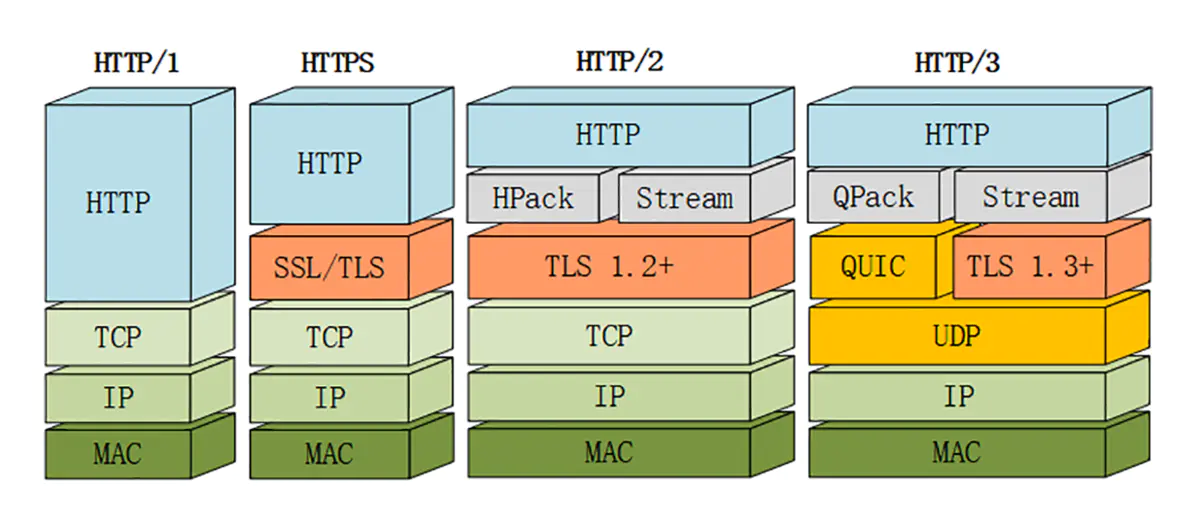
| 应用层 | 传输层 | 网络层 |
|---|---|---|
| HTTP | TCP | IP |
| HTTP/2 + TLS/1.2+ | TCP | IP |
| HTTP/3 + TLS/1.3 | QUIC(UDP) | IP |
- 🗑
TLS1.1- 由于安全因素,已经或将要废弃 - TLS 1.2 当今的主流版本
- TLS 1.3 简化了握手流程,增强了安全性
旧版本存在问题
虽然 HTTP/2 解决了很多之前旧版本的问题,但是它还是存在一个巨大的问题,主要是底层支撑的 TCP 协议造成的。HTTP/2 的缺点主要有以下两点:
- 建立连接的延时:HTTP/2 使用 TCP 协议来传输的,而如果使用 HTTPS 的话,还需要使用 TLS 协议进行安全传输,而使用 TLS 也需要一个握手过程,这样就需要有两个握手延迟过程
- 队头阻塞并没有彻底解决:在 HTTP/2 中,多个请求是跑在一个 TCP 管道中的。但当出现了丢包时,HTTP/2 的表现反倒不如 HTTP/1 了。因为 TCP 为了保证可靠传输,有个 丢包重传 机制,丢失的包必须要等待重新传输确认,HTTP/2 出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该 TCP 连接中的所有请求。而对于 HTTP/1.1 来说,可以开启多个 TCP 连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据
HTTP3 简介
Google 在推 SPDY 的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让 HTTP 跑在 QUIC 上而不是 TCP 上。 而这个“HTTP over QUIC”就是 HTTP 协议的下一个大版本,HTTP/3。
QUIC 虽然基于 UDP,但是在原本的基础上新增了很多功能,接下来我们重点介绍几个 QUIC 新功能。不过 HTTP/3 目前还处于草案阶段,正式发布前可能会有变动,所以本文尽量不涉及那些不稳定的细节。
新特性
零 RTT 建立连接
HTTP/2 的连接需要 3 RTT,如果考虑会话复用,即把第一次握手算出来的对称密钥缓存起来,那么也需要 2 RTT,更进一步的,如果 TLS 升级到 1.3,那么 HTTP/2 连接需要 2 RTT,考虑会话复用则需要 1 RTT。
有人会说 HTTP/2 不一定需要 HTTPS,握手过程还可以简化。这没毛病,HTTP/2 的标准的确不需要基于 HTTPS,但实际上所有浏览器的实现都要求 HTTP/2 必须基于 HTTPS,所以 HTTP/2 的加密连接必不可少。
而 HTTP/3 首次连接只需要 1 RTT,后面的连接更是只需 0 RTT,意味着客户端发给服务端的第一个包就带有请求数据,这一点 HTTP/2 难以望其项背。那这背后是什么原理呢?我们具体看下 QUIC 的连接过程。
- 首次连接时,客户端发送 Inchoate Client Hello 给服务端,用于请求连接;
- 服务端生成 g、p、a,根据 g、p 和 a 算出 A,然后将 g、p、A 放到 Server Config 中再发送 Rejection 消息给客户端;
- 客户端接收到 g、p、A 后,自己再生成 b,根据 g、p、b 算出 B,根据 A、p、b 算出初始密钥 K。B 和 K 算好后,客户端会用 K 加密 HTTP 数据,连同 B 一起发送给服务端;
- 服务端接收到 B 后,根据 a、p、B 生成与客户端同样的密钥,再用这密钥解密收到的 HTTP 数据。为了进一步的安全(前向安全性),服务端会更新自己的随机数 a 和公钥,再生成新的密钥 S,然后把公钥通过 Server Hello 发送给客户端。连同 Server Hello 消息,还有 HTTP 返回数据;
- 客户端收到 Server Hello 后,生成与服务端一致的新密钥 S,后面的传输都使用 S 加密。
这样,QUIC 从请求连接到正式接发 HTTP 数据一共花了 1 RTT,这 1 个 RTT 主要是为了获取 Server Config,后面的连接如果客户端缓存了 Server Config,那么就可以直接发送 HTTP 数据,实现 0 RTT 建立连接。
这里使用的是 DH 密钥交换算法,DH 算法的核心就是服务端生成 a、g、p 3 个随机数,a 自己持有,g 和 p 要传输给客户端,而客户端会生成 b 这 1 个随机数,通过 DH 算法客户端和服务端可以算出同样的密钥。在这过程中 a 和 b 并不参与网络传输,安全性大大提高。因为 p 和 g 是大数,所以即使在网络中传输的 p、g、A、B 都被劫持,那么靠现在的计算机算力也没法破解密钥。
连接迁移
TCP 连接基于四元组(源 IP、源端口、目的 IP、目的端口),切换网络时至少会有一个因素发生变化,导致连接发生变化。当连接发生变化时,如果还使用原来的 TCP 连接,则会导致连接失败,就得等原来的连接超时后重新建立连接,所以我们有时候发现切换到一个新网络时,即使新网络状况良好,但内容还是需要加载很久。如果实现得好,当检测到网络变化时立刻建立新的 TCP 连接,即使这样,建立新的连接还是需要几百毫秒的时间。
QUIC 的连接不受四元组的影响,当这四个元素发生变化时,原连接依然维持。那这是怎么做到的呢?道理很简单,QUIC 连接不以四元组作为标识,而是使用一个 64 位的随机数,这个随机数被称为 Connection ID,即使 IP 或者端口发生变化,只要 Connection ID 没有变化,那么连接依然可以维持。
队头阻塞和多路复用
队头阻塞会导致 HTTP/2 在更容易丢包的弱网络环境下比 HTTP/1.1 更慢!
那 QUIC 是如何解决队头阻塞问题的呢?主要有两点。
- QUIC 的传输单元是 Packet,加密单元也是 Packet,整个加密、传输、解密都基于 Packet,这样就能避免 TLS 的队头阻塞问题
- QUIC 基于 UDP,UDP 的数据包在接收端没有处理顺序,即使中间丢失一个包,也不会阻塞整条连接,其他的资源会被正常处理
拥塞控制
拥塞控制的目的是避免过多的数据一下子涌入网络,导致网络超出最大负荷。QUIC 的拥塞控制与 TCP 类似,并在此基础上做了改进。所以我们先简单介绍下 TCP 的拥塞控制。
TCP 拥塞控制由 4 个核心算法组成:慢启动、拥塞避免、快速重传和快速恢复,理解了这 4 个算法,对 TCP 的拥塞控制也就有了大概了解。
- 慢启动:发送方向接收方发送 1 个单位的数据,收到对方确认后会发送 2 个单位的数据,然后依次是 4 个、8 个……呈指数级增长,这个过程就是在不断试探网络的拥塞程度,超出阈值则会导致网络拥塞;
- 拥塞避免:指数增长不可能是无限的,到达某个限制(慢启动阈值)之后,指数增长变为线性增长;
- 快速重传:发送方每一次发送时都会设置一个超时计时器,超时后即认为丢失,需要重发;
- 快速恢复:在上面快速重传的基础上,发送方重新发送数据时,也会启动一个超时定时器,如果收到确认消息则进入拥塞避免阶段,如果仍然超时,则回到慢启动阶段。
QUIC 重新实现了 TCP 协议的 Cubic 算法进行拥塞控制,并在此基础上做了不少改进。下面介绍一些 QUIC 改进的拥塞控制的特性。
热插拔
TCP 中如果要修改拥塞控制策略,需要在系统层面进行操作。QUIC 修改拥塞控制策略只需要在应用层操作,并且 QUIC 会根据不同的网络环境、用户来动态选择拥塞控制算法。
前向纠错 FEC
QUIC 使用前向纠错(FEC,Forward Error Correction)技术增加协议的容错性。一段数据被切分为 10 个包后,依次对每个包进行异或运算,运算结果会作为 FEC 包与数据包一起被传输,如果不幸在传输过程中有一个数据包丢失,那么就可以根据剩余 9 个包以及 FEC 包推算出丢失的那个包的数据,这样就大大增加了协议的容错性。
这是符合现阶段网络技术的一种方案,现阶段带宽已经不是网络传输的瓶颈,往返时间才是,所以新的网络传输协议可以适当增加数据冗余,减少重传操作。
单调递增的 Packet Number
TCP 为了保证可靠性,使用 Sequence Number 和 ACK 来确认消息是否有序到达,但这样的设计存在缺陷。
超时发生后客户端发起重传,后来接收到了 ACK 确认消息,但因为原始请求和重传请求接收到的 ACK 消息一样,所以客户端就郁闷了,不知道这个 ACK 对应的是原始请求还是重传请求。如果客户端认为是原始请求的 ACK,但实际上是左图的情形,则计算的采样 RTT 偏大;如果客户端认为是重传请求的 ACK,但实际上是右图的情形,又会导致采样 RTT 偏小。图中有几个术语,RTO 是指超时重传时间(Retransmission TimeOut),跟我们熟悉的 RTT(Round Trip Time,往返时间)很长得很像。采样 RTT 会影响 RTO 计算,超时时间的准确把握很重要,长了短了都不合适。
QUIC 解决了上面的歧义问题。与 Sequence Number 不同的是,Packet Number 严格单调递增,如果 Packet N 丢失了,那么重传时 Packet 的标识不会是 N,而是比 N 大的数字,比如 N + M,这样发送方接收到确认消息时就能方便地知道 ACK 对应的是原始请求还是重传请求。
ACK Delay
TCP 计算 RTT 时没有考虑接收方接收到数据到发送确认消息之间的延迟,如下图所示,这段延迟即 ACK Delay。QUIC 考虑了这段延迟,使得 RTT 的计算更加准确。
更多的 ACK 块
一般来说,接收方收到发送方的消息后都应该发送一个 ACK 回复,表示收到了数据。但每收到一个数据就返回一个 ACK 回复太麻烦,所以一般不会立即回复,而是接收到多个数据后再回复,TCP SACK 最多提供 3 个 ACK block。但有些场景下,比如下载,只需要服务器返回数据就好,但按照 TCP 的设计,每收到 3 个数据包就要“礼貌性”地返回一个 ACK。而 QUIC 最多可以捎带 256 个 ACK block。在丢包率比较严重的网络下,更多的 ACK block 可以减少重传量,提升网络效率。
流量控制
TCP 会对每个 TCP 连接进行流量控制,流量控制的意思是让发送方不要发送太快,要让接收方来得及接收,不然会导致数据溢出而丢失,TCP 的流量控制主要通过滑动窗口来实现的。可以看出,拥塞控制主要是控制发送方的发送策略,但没有考虑到接收方的接收能力,流量控制是对这部分能力的补齐。
QUIC 只需要建立一条连接,在这条连接上同时传输多条 Stream,好比有一条道路,两头分别有一个仓库,道路中有很多车辆运送物资。QUIC 的流量控制有两个级别:连接级别(Connection Level)和 Stream 级别(Stream Level),好比既要控制这条路的总流量,不要一下子很多车辆涌进来,货物来不及处理,也不能一个车辆一下子运送很多货物,这样货物也来不及处理。
那 QUIC 是怎么实现流量控制的呢?我们先看单条 Stream 的流量控制。Stream 还没传输数据时,接收窗口(flow control receive window)就是最大接收窗口(flow control receive window),随着接收方接收到数据后,接收窗口不断缩小。在接收到的数据中,有的数据已被处理,而有的数据还没来得及被处理。如下图所示,蓝色块表示已处理数据,黄色块表示未处理数据,这部分数据的到来,使得 Stream 的接收窗口缩小。
随着数据不断被处理,接收方就有能力处理更多数据。当满足 (flow control receive offset - consumed bytes) < (max receive window / 2) 时,接收方会发送 WINDOW_UPDATE frame 告诉发送方你可以再多发送些数据过来。这时 flow control receive offset 就会偏移,接收窗口增大,发送方可以发送更多数据到接收方。
Stream 级别对防止接收端接收过多数据作用有限,更需要借助 Connection 级别的流量控制。理解了 Stream 流量那么也很好理解 Connection 流控。Stream 中,接收窗口(flow control receive window) = 最大接收窗口(max receive window) - 已接收数据(highest received byte offset) ,而对 Connection 来说:接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + ... + StreamN 接收窗口 。