聚合管道
先介绍管道的概念,在 POSIX 多线程的使用方式中,定义了一种重要的 pipeline 方式,成为 流水线 或 管道,这种方式使得数据被一组线程顺序执行。
Input -> ThreadA -> ThreadB -> ThreadC -> Output
以面向对象的思想去理解,整个流水线,可以理解为一个数据传输的管道;该管道中的每一个工作线程,可以理解为一个整个流水线的一个工作阶段 stage,这些工作线程之间的合作是一环扣一环的。靠输入口越近的工作线程,是时序较早的工作阶段 stage,它的工作成果会影响下一个工作线程阶段(stage)的工作结果,即下个阶段依赖于上一个阶段的输出,上一个阶段的输出成为本阶段的输入。这也是 pipeline 的一个共有特点。
聚合框架
Mongodb 在 2.2 版本中引入了 聚合框架(aggregate framework)的新功能,它是聚合的新框架,其概念类似于数据处理的管道,每个文档经过一个由多个节点组成的管道,每个节点相当于流水线中的一个 stage,有自己的功能(分组、过滤等),文档经过管道处理后,最后输出相应的结果,管道的基本功能有两个:
- 对文档进行过滤,筛选出合适的文档
- 对文档进行变换,改变文档的输出形式
其他的一些功能还包括按照某个指定的字段分组和排序等。而且在每个阶段还可以使用表达式操作符计算平均值和拼接字符串等相关操作。
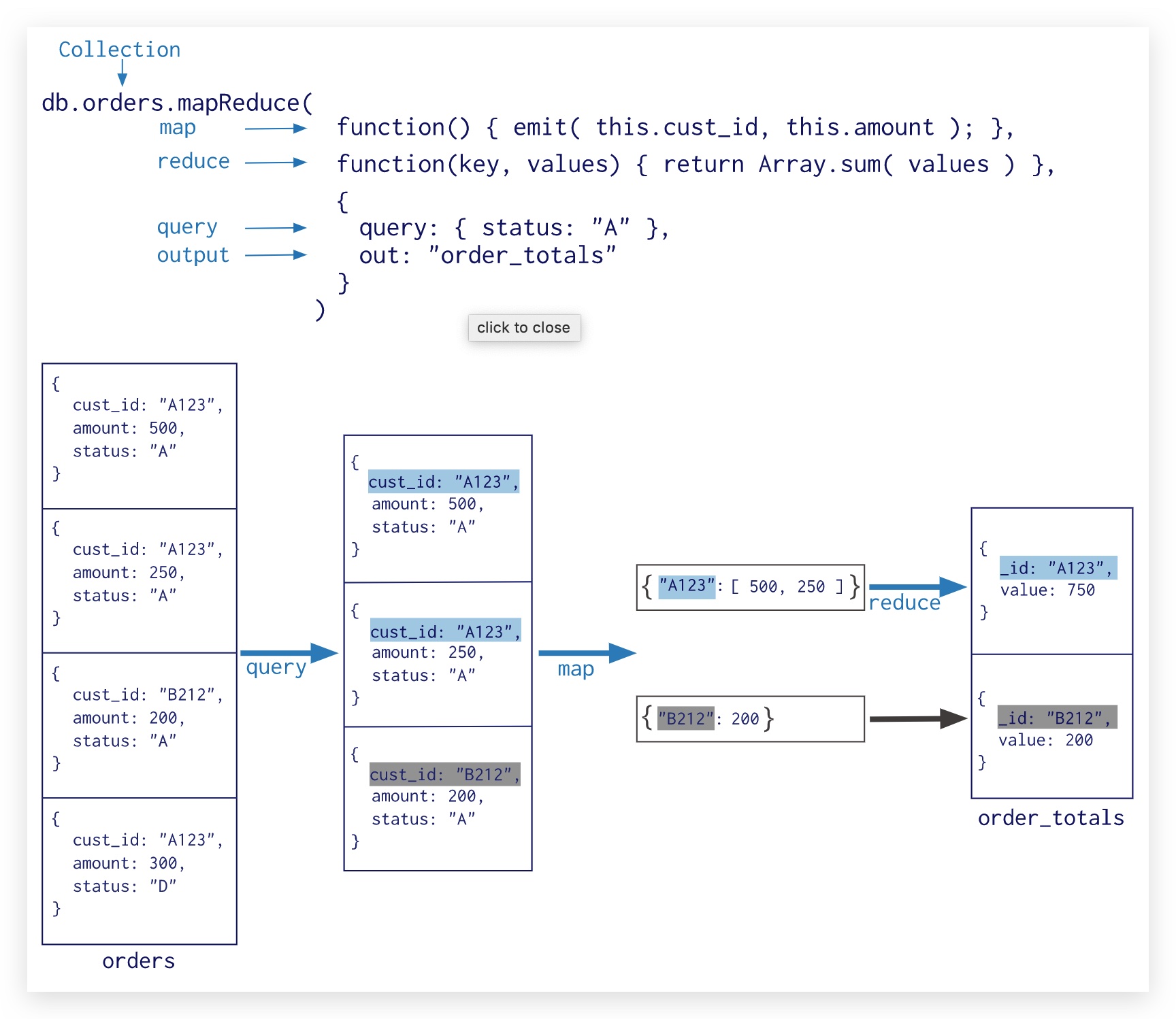
管道提供了一个 MapReduce 的替代方案,MapReduce 使用相对来说比较复杂,而管道的拥有固定的接口(操作符表达),使用比较简单,对于大多数的聚合任务管道一般来说是首选方法。
MongoDB 中的聚合主要用于简单的数据处理(平均值,求和等),并返回计算后的数据结果,类似于 SQL 中的内嵌函数(count() 等)。
🌰 MongoDB 官网给出了聚合框架的应用实例:
聚合表达式
字段路径表达式
| 字段路径表达式 | 说明 |
|---|---|
$<field> | 使用 $ 来指示字段路径 |
$<field>.<sub-field> | 使用 $ 和 . 来指示内嵌文档字段路径 |
系统变量表达式
| 系统变量表达式 | 说明 |
|---|---|
$$<variable> | 使用 $$ 来指示系统变量 |
$$CURRENT | 指示管道中当前操作的文档 |
常量表达式
| 常量表达式 | 说明 |
|---|---|
$literal: <value> | 指示常量 <value> |
$literal: "$name" | 指示常量字符串 " |
表达式操作符
| 常用表达式 | 说明 |
|---|---|
$sum | 计算总和,{$sum: 1} 表示返回总和 x 1 的值,使用 { $sum: '$指定字段' } 也能直接获取指定字段的值的总和 |
$avg | 求平均值 |
$min | 求最小值 |
$max | 求最大值 |
$push | 将结果文档中插入值到一个数组中 |
$first | 根据文档的排序获取第一个文档数据 |
$last | 同理,获取最后一个文档数据 |
聚合管道阶段
$project
$project 管道操作符用于修改流中的文档。
对文档进行重新投影,主要用于重命名、增加字字段、删除字段。
# 隐藏文档 class 主键,显示 age 字段值# 添加新字段 name,值为原文档中字段 info 中的 name 的值$ db.class.aggregate([{$project: {_id: 0,age: 1,name: "$info.name",}}])# 同样地,隐藏文档 class 主键,显示 age 字段值# 添加新字段 sub,其数据类型为数组,也以对应 subject 的对象键值填充# 当不存在字段,会使用 null 填充$ db.class.aggregate([{$project: {_id: 0,age: 1,sub: ["$subject.chinese","$subject.maths","$subject.english"]}}])
$project 是很常用的聚合阶段,可以用来灵活地控制输出文档的格式,也可以用来提出不相关的字段,以优化聚合管道操作的性能。
$match
$match 中使用的文档筛选语法,和读取文档时的 $match 语法相同。主要用于过滤、筛选符合条件的文档,作为下一阶段的输入。
⚠️ 注意:由于 aggregate 管道对于内存的限制,在处理大文件的时候,最好先用 $match 操作符进行筛选,减少内存占用。
# 匹配 class 文档字段(嵌套文档) <field> 的字段 <sub-field> 的值为 <value> 的文档$ db.class.aggregate([{$match: {"<field>.<sub-field>": <value>}}])$ db.class.aggregate([{$match: {$or: [{<field1>: {<comparasion-operator1>: <value1>,<comparasion-operator2>: <value2>}}, {"<field2>.<sub-field2>": <value3>}]"<field>.<sub-field>": <value>}}])
$match 常常用于剔除或保留某篇文档。应该尽量在聚合管道的开始阶段应用 $match,这样可以减少后续阶段中需要处理的文档数量,优化聚合操作的性能。
⚠️ 注意事项:
- 不能在
$match操作符中使用$where表达式操作符 $match应该尽可能在管道查询的前置阶段,可以提早过滤文档,减少后续阶段操作文档,加快聚合速度- 如果
$match出现在最前面的话,可以使用索引来加快查询
limit 和 skip
$limt 和 $skip 通常在一起使用。
$limit 用于限制经过管道的文档的数量。
$skip 用于待操作集合处理前跳过部分的文档。
# 筛选 <number> 篇文档$ db.<collection>.aggregate([{ $limit: <number> }])# 跳过 <number> 篇文档$ db.<collection>.aggregate([{ $skip: <number> }])
$unwind
将数组拆分成独立字段。
# 如果原文档中对应的 <field> 字段是数组,那么就会将数组中每个元素,生成新的文档,对应的 <field> 为展开的数组成员# 新生成的文档文档主键都是一致的,区别在于 <field> 的不同# 如果原文档中对应的 <field> 字段为非数组,那么不会有其他操作,直接保留下来$ db.<collection>.aggregate([{$unwind: {path: "$<field>"}}])# 同上,但是展开后会添加一个新字段 <field-item-index>,为原文档数组中的索引数值# 如果原文档对应 <field> 不是数组类型,新增的字段默认填充 null$ db.<collection>.aggregate([{$unwind: {path: "$<field>",includArrayIndex: <field-item-index>}}])# 展开数组时保留空数组或不存在数组的文档$ db.<collection>.aggregate([{$unwind: {path: "$<field>",preserveNullAndEmptyArrays: true}}])
$sort
对文档按照指定字段排序,与查询文档 find() 时的 sort 相同。
1:由小到大-1:由大到小
# 对文档进行排序$ db.<collection>.aggregate([{$sort: {<field1>: <sort-number>,"<field2>.<sub-field>": <sort-number>}}])
$lookup
使用单一字段值进行查询
$lookup: {# 同一数据库中的另一个查询集合(不能跨数据库查询)from: <collection to join>,# 管道文档中用来查询的字段localField: <field from the input docuement>,# 查询集合中的查询字段foreignField: <field from the documents of the "from" collection>,# 写入管道文档中的查询结果数组字段as: <output array field>}
如下面代码所示:
MongoDB 会先管道查询 <aggregation-collection> 集合(这里我们称为管道集合),同时也会查询另一个集合 <find-collection>(这里我们称为查询集合)。当管道集合文档中的字段 <aggregation-field> 与查询集合文档中的字段 <find-field> 相匹配时,这篇查询集合中的文档就是符合查询条件的文档,那么就会将这篇文档添加到管道集合对应文档的 <new-field> 字段中。而 <new-field> 的内容就根据查询结果而有所不同,
$ db.<aggregation-collection>.aggregate([{$lookup: {from: "<find-collection>",localField: "<aggregation-field>",foreignField: "<find-field>",as: "<new-field>"}}])
- 如果管道集合的
<local-field>字段是个数组字段,查询集合的<find-field>字段是字符串字段,<local-field>多个成员与查询集合中的<find-field>相匹配,那么会将查询集合中这几个字段匹配的文档组成数组,赋值到管道集合文档的<new-field>新字段中。 - 如果都没有对应符合条件的
<find-collection>文档,那么<aggregation-collection>的文档也会保留下来,但是<new-field>字段会是空数组
# 如果 localField 是一个数组字段# 使用 $unwind 将 <aggregation-collection> 的 <aggregation-field> 数组字段展开$ db.<aggregation-collection>.aggregate([{$unwind: {path: "$<aggregation-field>"}},{$lookup: {from: <find-collection>,localField: <aggregation-field>,foreignField: <find-field>,as: <new-field>}}])
先经过 $unwind 会先把管道集合中 <aggregation-collection> 文档中无法展开的 <aggregation-field> 字段的值的对应文档剔除。
使用复杂条件进行查询
let 是在对 pipeline 进行进一步聚合查询时需要用到原管道查询时使用到的文档的字段值时使用的,是用于对原管道查询时所在文档的字段进行再次声明。
$lookup: {from: <collection to join>,# 对查询集合中的文档使用聚合阶段进行处理时,如果需要参考管道文档中的字段,则必须使用 let 参数对字段进行声明let: { <var_1: <expression>, ..., <var_n>: <expression> },# 对查询集合中的文档使用聚合阶段进行查询(针对 from 指定的集合中的文档)pipeline: [<pipeline to execute on the collection to join>],as: <output array field>}
🌰 示例:
# 对 <find-collection> 以 $match 做筛选做示例$ db.<aggregation-collection>.aggregate([{$lookup: {from: <find-collection>,pipeline: [{$match: {<field>: <value>}}],as: <new-field>}}])# <find-collection-field> 查询集合中文档的字段# <var-aggregation-field> 是原文档重新声明的字段(相当于一个间接变量)$ db.<aggregation-collection>.aggregate([{$lookup: {from: <find-collection>,let: { <var-aggregation-field>: "$<aggregation-field>" },# pipeline 中所有聚合管道阶段都是应用在查询集合pipeline: [{$match: {$expr: {$and: [{ $eq: [ "$<find-collection-field>", <value1> ] },{ $gt: [ "$$<var-aggregation-field>", <value2> ] }]}}}],as: <new-field>}}])
$group
使用 $group 操作符必须指定 _id 域,同时也可以包含一些算术类型的表达式操作符。
$group: {# 定义分组规则_id: <expression>,# 可以使用聚合操作符来定义新字段<field1>: { <accumulator1>: <expression1> },...}
🌰 示例:
通过管道集合的 <collection-field> 字段对数据进行分组。
不实用聚合操作符的情况下,$group 可以返回管道文档中某一字段的所有(不重复的)值。
# 基本使用方法$ db.<collection>.aggregate([{$group: {<new-field>: "$<collection-field>"}}])
下面以实际例子演示:
# 高级用法,使用聚合操作符计算分组聚合值$ db.<collection>.aggregate([{$group: {# 赋值为 null 时,不会分组,所有管道文档分为一组_id: "$currency",# 每篇文档的 qty 字段求和结果,赋值 totalQty 新字段totalQty: { $sum: "$qty" },# 每篇文档的 price 和 qty 的乘积的求和结果totalNotional: { $sum: { $multiply: [ "$price", "$qty" ] } },# 每篇文档的 price 字段求得平均数avgPrice: { $avg: "$price" },# 每篇文档 +1,多少篇就加多少次,集合文档的总数count: { $sum: 1 },# 找到分组中某个表达式中最大的值maxNotional: { $max: { $multiply: [ "$price", "$qty" ] } },#找到分组中某个表达式中最小的值minNotional: { $min: { $multiply: [ "$price", "$qty" ] } },}}])
⚠️ 注意事项:
$group的输出是无序的$group操作目前是在内存中进行的,所以不能用它来对大量个数的文档进行分类- 必须指定
_id域
$out
创建指定副本集合
$ db.<collection>.aggregate([{$group: {_id: "$<field1>",# <field2> 是数组字段<new-field>: { $push: "$<field2>" }}},{# 副本集合名称$out: "output"}])
🌰 实例:
# 已有集合{ "_id" : 8751, "title" : "The Banquet", "author" : "Dante", "copies" : 2 }{ "_id" : 8752, "title" : "Divine Comedy", "author" : "Dante", "copies" : 1 }{ "_id" : 8645, "title" : "Eclogues", "author" : "Dante", "copies" : 2 }{ "_id" : 7000, "title" : "The Odyssey", "author" : "Homer", "copies" : 10 }{ "_id" : 7020, "title" : "Iliad", "author" : "Homer", "copies" : 10 }# 按照 author 分组,然后 out 一个新集合 authors$ db.books.aggregate([{ $group: { _id: "$author", books: { $push: "$title" } } },{ $out: "authors" }])# 查询结果{ "_id" : "Homer", "books" : [ "The Odyssey", "Iliad" ] }{ "_id" : "Dante", "books" : [ "The Banquet", "Divine Comedy", "Eclogues" ] }
配置项
每个聚合管道阶段使用的内存不能超过 100MB。
如果数据量较大,为了防止聚合管道阶段超出内存上限并且抛出错误,可以启用 allowDiskUse 选项。
allowDishUse 启用之后,聚合阶段可以再内存容量不足时,将操作数据写入临时文件中。
临时文件会被写入 dbPath 下的 _tmp 文件夹,dbPath 的默认值为 /data/db。
聚合操作的优化
顺序优化
$project + $match
既需要使用 $project,也需要 $match 阶段,MongoDB 在运行聚合管道代码时,尽量把 $match 阶段设置在 $project 阶段之前运行。因为 $match 是对文档进行筛选,所以 $match 阶段很有可能减少文档数量,那么如果我们要尽量减少操作量,那么就需要尽可能早地阶段减少文档进入后续的阶段。
$sort + $match
同理,把 $match 提前到 $sort 阶段前,能有效优化。
$project + $skip
$skip 阶段在 $project 阶段之前运行。
合并优化
$sort + $limit
如果两者之间没有夹杂着改变文档数量的聚合阶段,$sort 和 $limit 阶段可以合并。
同类型的,如下组合也可以进行优化:
$limit+$limit$skip+$skip$match+$match
连续的 $limit、$skip 或 $skip 阶段排列在一起时,可以合并为一个阶段。
$lookup 和 $unwind
连续排列在一起的 $lookup 和 $unwind 阶段,如果 $unwind 应用在 $lookup 阶段创建的 as 字段上,则两者可以合并。
参考资料:
https://segmentfault.com/a/1190000020685264?utm_source=tag-newest
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。$match:用于过滤数据,只输出符合条件的文档。$match 使用 MongoDB 的标准查询操作。$limit:用来限制 MongoDB 聚合管道返回的文档数。$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。$group:将集合中的文档分组,可用于统计结果。$sort:将输入文档排序后输出。$geoNear:输出接近某一地理位置的有序文档。